First Experience With Machine Learning Models
Published on 09 Apr 2020

First Experience With Machine Learning Models
Everyone today is talking about “Machine Learning” and how to benefit from it in various industries. Systango is currently working with many clients helping them with implementing machine learning in web development especially in the finance and healthcare industries. We all know what machine learning is all about but when you try to understand its implementation, it’s confusing.
In this article, we will help you understand machine learning in web development by implementing Machine Learning Models using two iconic problems: Iris Flower Classification Problem and Abalone Dataset.
We hear the term Machine Learning every day, before we get into the technical details of implementing various Machine Learning Algorithms, let’s look at some applications of machine learning in web development present in our everyday lives:
- The self-driving/Autonomous Cars that everyone from Google to Uber are working on. Built completely on top of machine learning.
- We get all these recommendations on Amazon or Netflix or every other website for that matter. Machine learning in web development applied.
- All these hashtag trends on Social Media Platforms. Machine learning along with linguistic rules.
- Fraud detection. An important Machine Learning use case today.
The Two Machine Learning Models – Iris Flower Dataset and Abalone Dataset
To get a basic understanding of how machine learning in web development works, we will be looking at two of the iconic machine learning models.
Iris Flower Dataset – This is a basic classification problem where we predict the species of flower based on
- measurements of length and width of the sepals
- Measurements of length and width of petals.
A classification problem is the one where our prediction has to be in a given class like [boy, girl], [cat, dog] or in this case like [Iris Setosa, Iris Versicolour, Iris Virginica].
Abalone Dataset – This dataset involves predicting the age of abalone, a shellfish based on its physical attributes. The age of an Abalone is determined by counting the number of rings in the shell, which is what we will predict.
Note– The abalone dataset is usually solved as a classification problem, with the number of rings (1,2,3…n) being classes, but for the sake of understanding be will consider this as an estimation problem.
Libraries Needed for Building Machine Learning Models:
Sklearn or Scikit-learn
Sklearn is one of the major libraries used for machine learning in web development. You can find its official documentation here. The great thing about sklearn other than its documentation (which itself deserves a lot of praise), is the community support. Sklearn has been around for more than a decade now, and in this time, its community has grown many folds. Sklearn comes pre-loaded with the datasets we will be working on, so you probably won’t require a CSV to begin with.
Other than sklearn, we will also be using NumPy, and pandas for some data processing.
Algorithms We Will Be Using:
To understand the Iris flower and abalone problems, we will be using the two algorithms: K nearest neighbor and Linear Regression in Machine Learning.
K Nearest Neighbours
It is the most basic algorithm used for classification problems.
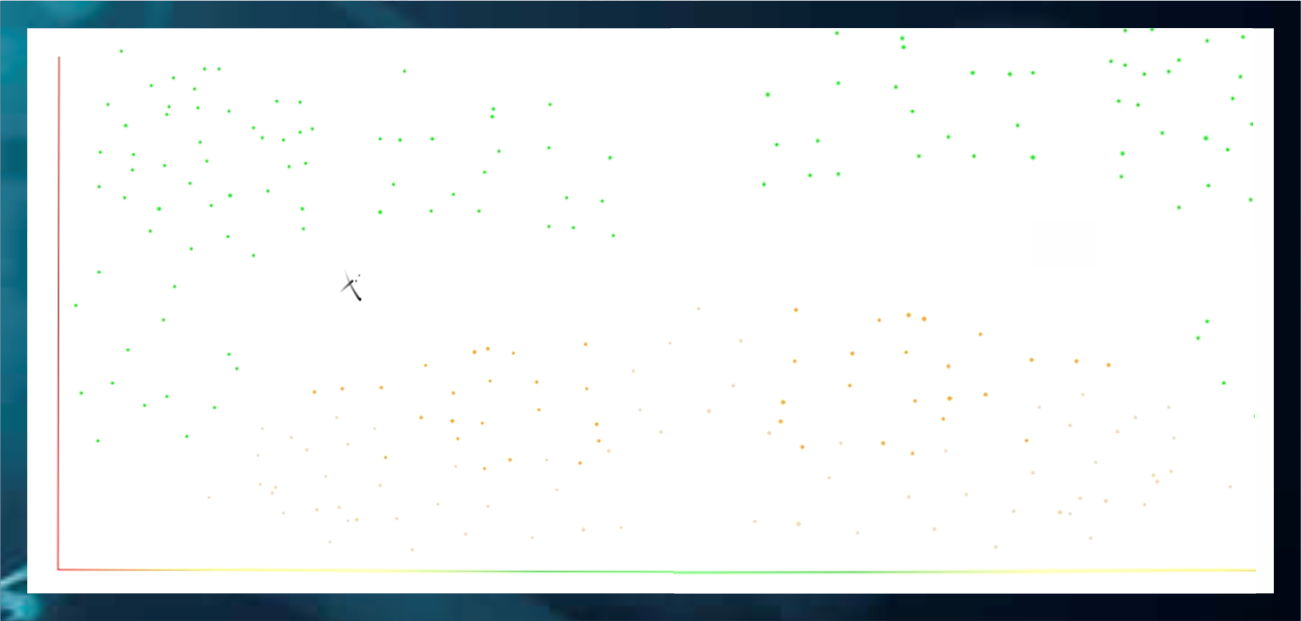
Consider the problem:
A company is taking a test for recruitment; it gives out the same set of questions for beginners, as well as experienced candidates.
- X-axis – the experience of a candidate
- Y-axis – number of questions they solved correctly
The following graph depicts whether the candidates were selected or not.
- Green – selected
- Brown – not selected
Now suppose you are at the point X, to predict whether you will be selected or not, KNN says that your class will be that of your K nearest neighbor. So for K=1, we will consider the point closest to the cross and assume that the class of that point is the class of X.
Similarly, for k=2, we will consider the nearest two data points, and so on. Note that the value of K has nothing to do with the dataset, and is a property of the algorithm. Such parameters are known as hyperparameters.
Linear Regression in Machine Learning
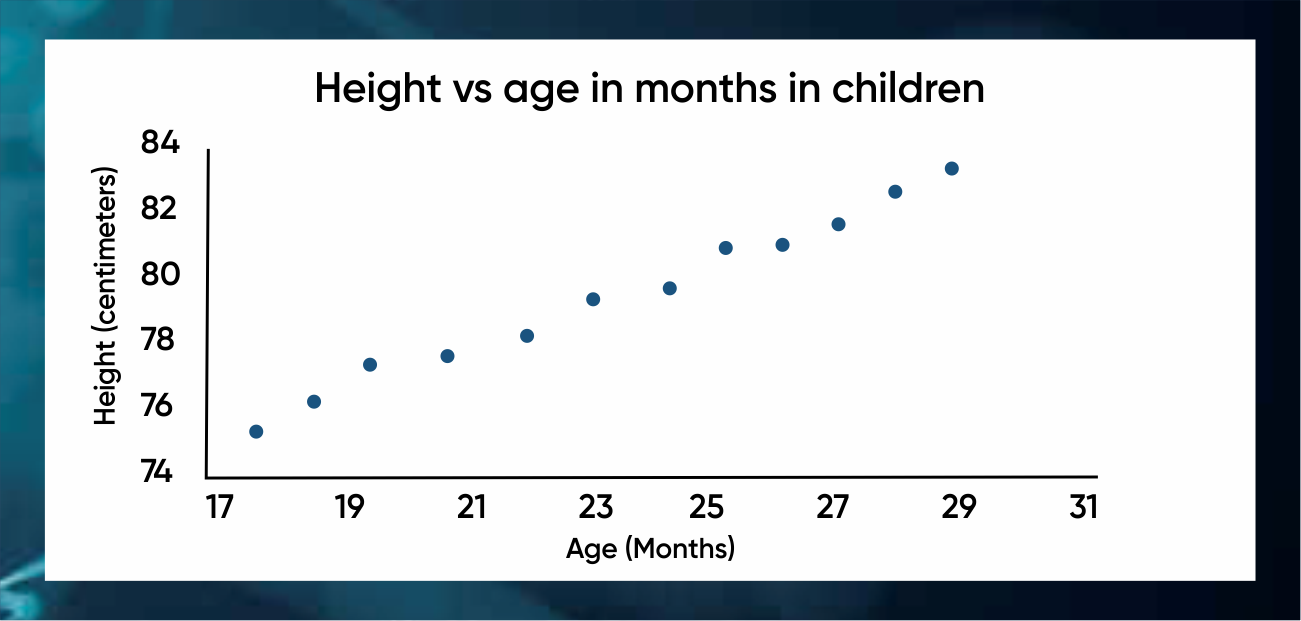
Linear regression in machine learning is a common prediction algorithm used for estimation. It assumes that columns are highly correlated meaning that if one increases/decreases the other also increases/decreases.
- X-axis – age of children
- Y-axis – their height (represented with blue dots).
What linear regression in machine learning says is that there is a line very much like y=mx+c, that passes from this plane in such a way that all these points are equidistant from it. So, whenever you need to predict someone’s height based on their age, all you need to do is to find the point in the line, closest to that age.
The Machine Learning Cycle
Feature Selection – The first step is to select what all “attributes” or columns of a table, are actually useful for making predictions. There are many ways to select features like Variance Selection, Recursive Feature Selections, all of which are supported by sklearn.
Model Selection – Once you have decided on the columns that you will use for prediction, the next step is to select an algorithm. In sklearn, the classes that implement these algorithms are called estimators. These are selected on a number of criteria, ranging from the type of problem to the relationships between the features.
Hyperparameter Tuning – After selecting your model, you need to set the hyperparameters, and also ensure that the estimator does not overfit.
Test your model – A common practice is to divide your dataset into two separate datasets: Training Dataset and Testing Dataset, which is usually in the ratio 80:20. If your test dataset gives good predictions, you are good to go, else you need to repeat the cycle.
Implementation of these Machine Learning Models
Now, let’s look at the step-by-step implementation of both the Machine Learning Models:
Iris Data Classification:
- Import the libraries:
import pandas as pd
from sklearn import preprocessing
import numpy as np
import numpy.random as nr
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
2.
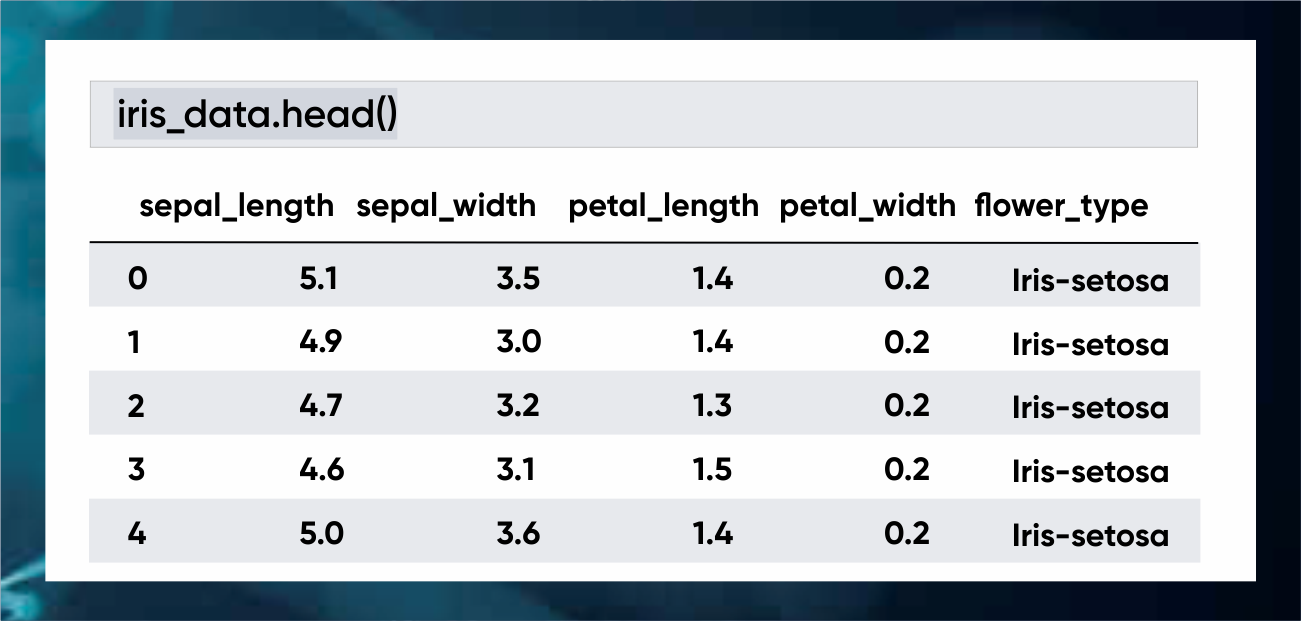
Upon looking at the data-set you realize that the flower-type is not numeric. We need to convert it to numbers. Sklearn comes with the labels to numerical data.
iris_data[‘flower_type’] = iris_data[‘flower_type’].fillna(”)
labelencoder = LabelEncoder()
iris_data[‘flower_type_encoded’] = labelencoder.fit_transform(iris_data[“flower_type”])
- Now we need to scale the data, to ensure that all the features are in the same range.
num_cols = [‘sepal_length’, ‘sepal_width’, ‘petal_length’,’petal_width’]
iris_data_scaled = scale(iris_data.drop([‘flower_type’,’flower_type_encoded’], axis=1))
iris_data_scaled = pd.DataFrame(iris_data_scaled, columns = num_cols)
- Split the data into two separate datasets, test and train.
np.random.seed(3456)
iris_split = train_test_split(np.asmatrix(iris_data_scaled), test_size = 75)
iris_train_features = iris_split[0][:, :4]
iris_train_labels = np.ravel(iris_split[0][:, 4])
iris_test_features = iris_split[1][:, :4]
iris_test_labels = np.ravel(iris_split[1][:, 4])
- Finally, it’s time to train our model. After multiple hyperparameter trials, I found that K=3 serves the best results without overfitting the data.
KNN_mod = KNeighborsClassifier(n_neighbors = 3)
KNN_mod.fit(iris_train_features, iris_train_labels)
WHY SYSTANGO?
In the healthcare industry, wearable devices and sensors produce data that is being used to assess a patient’s health in real-time. If you want to empower medical experts or improve diagnostics or treatment, get in touch and understand how Systango can help you!

- And it’s time to test the accuracy of our model, the following small snippet will do that:
iris_test[‘predicted’] = KNN_mod.predict(iris_test_features)
iris_test[‘correct’] = [1 if x == z else 0 for x, z in zip(iris_test[‘predicted’], iris_test_labels)]
accuracy = 100.0 * float(sum(iris_test[‘correct’])) / float(iris_test.shape[0])
print(accuracy)
Through this method, I was able to get an accuracy of 96%.
Abalone Data Estimation
- Import the following:
import pandas as pd
from sklearn import linear_model
import sklearn.metrics as sklm
import numpy as np
import numpy.random as nr
import math
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import scale
2.
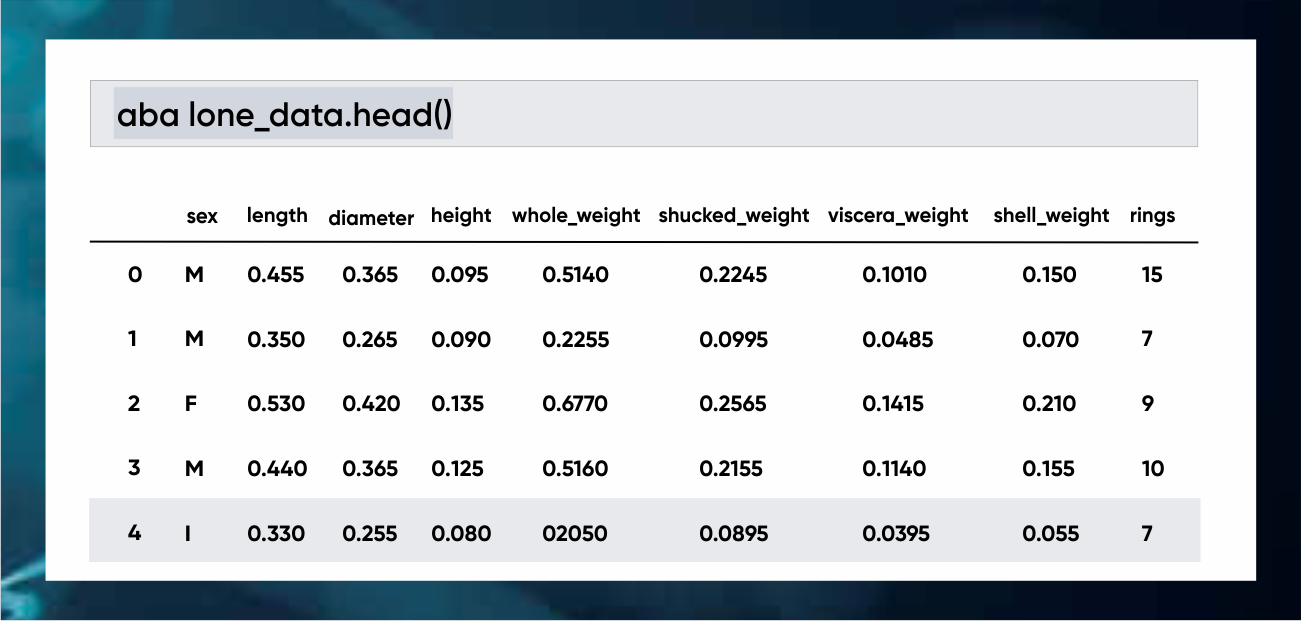
Just like the iris problem, we need to encode our categorical values. As you can see the sex of the abalone is the only categorical values here.
abalone_data[‘sex’] = abalone_data[‘sex’].fillna(”)
labelencoder = LabelEncoder()
abalone_data[‘sex_encoded’] = labelencoder.fit_transform(abalone_data[“sex”])
- Scale the data to ensure that all the features are in the same range.
num_cols = [‘sex_encoded’, ‘length’, ‘diameter’, ‘height’, ‘whole_weight’, ‘shucked_weight’,’viscera_weight’, ‘shell_weight’]
alabone_data_scaled = scale(abalone_data.drop([‘sex’,’sex_encoded’], axis=1))
alabone_data_scaled = pd.DataFrame(alabone_data_scaled, columns = num_cols)
- Split it into two separate datasets, test and train.
nr.seed(785)
labels = np.array(abalone_data[‘rings’])
indx = range(Features.shape[0])
indx = ms.train_test_split(indx, test_size = 1100)
x_train = Features[indx[0][:]]
y_train = np.ravel(labels[indx[0]])
x_test = Features[indx[1][:]]
y_test = np.ravel(labels[indx[1]])
- Model training.
lin_mod = linear_model.LinearRegression(fit_intercept = True)
lin_mod.fit(x_train, y_train)
Why Systango?
We are currently working with many clients in the Finance Industry for 2 main objectives: identify important insights in data and to prevent fraud. If you are not sure about how Machine Learning benefits your business, get in touch, and get insights for free!
- Error Calculation – unlike a classification problem, the accuracy of an estimation problem is calculated from its error. The following code will provide more clarity :
def print_metrics(y_true, y_predicted):
print(‘Mean Square Error = ‘ + str(sklm.mean_squared_error(y_true, y_predicted)))
print(‘Root Mean Square Error = ‘ + str(math.sqrt(sklm.mean_squared_error(y_true, y_predicted))))
print(‘Mean Absolute Error = ‘ + str(sklm.mean_absolute_error(y_true, y_predicted)))
print(‘Median Absolute Error = ‘ + str(sklm.median_absolute_error(y_true, y_predicted)))
y_score = lin_mod.predict(x_test)
print_metrics(y_test, y_score)
So here, my RMSE (Root Mean Square Error) was around 2.
Well, you are now familiar with two very common algorithms used frequently to implement Machine Learning in web development. In order to move forward from here, you could look into the various sklearn methods for Feature selection. There is also a hyperparameter search, which allows you to select the best hyperparameters based on the dataset (look into GridSearchCV by sklearn).
If you need to implement some complex Algorithms and use cases of Machine Learning in web development for your business to enable better predictability or better decision making from the available data or have any other questions, feel free to get in touch.
Related posts

Blockchain
Web Apps
NFT
App Development
The Ultimate Guide to Hiring Blockchain Developers in 2025: Skills, Costs, and Models
15 Apr 2025

App Development
Mobile Apps
Technology
Web Apps
Building Your App? Rust vs Go: A Guide for Business Owners
21 Feb 2024
Let’s talk, no strings attached.
