

Do You Think Hosting on Google App Engine is a Pricey Affair? Here’s How To Fix It!
Last Updated on: July 22, 2020

Google App Engine offers a number of great features for Python stack projects, but it’s often criticised for its high cost compared to other cloud-based platforms. But developers shouldn’t dismiss App Engine entirely since along with the ease of use, developers can enjoy a more streamlined performance and common configurations without the massive bill looming at the end. In this article i reflect on how we made a few configuration tweaks to Google App Engine and ultimately dropped our costs to a fifth of what they were.
The instance-related parameters I’ve defined below are major components for controlling the performance and cost of an App Engine application.
But how do you actually configure the application?
We can start to make informed decisions thanks to the metrics available in the App Engine Dashboard, including:
- Request rate (number of requests per second)
- Traffic (bytes per second)
- Latency of the application
An illustrated example:
One B2B application we worked on recently has around 10,000-12,000 active accounts and is highly data-intensive, priming with 80 requests per second. To give you an idea of how vital performance was to this app, it was used by Target for their Black Friday sales around the Thanksgiving holiday. During this time, the number of requests peaked at 250 requests/second and our App Engine configurations allowed it to scale efficiently without degrading performance.
Even with this surge in usage, we were able to keep the hosting budget affordable.
Here’s how we did it:
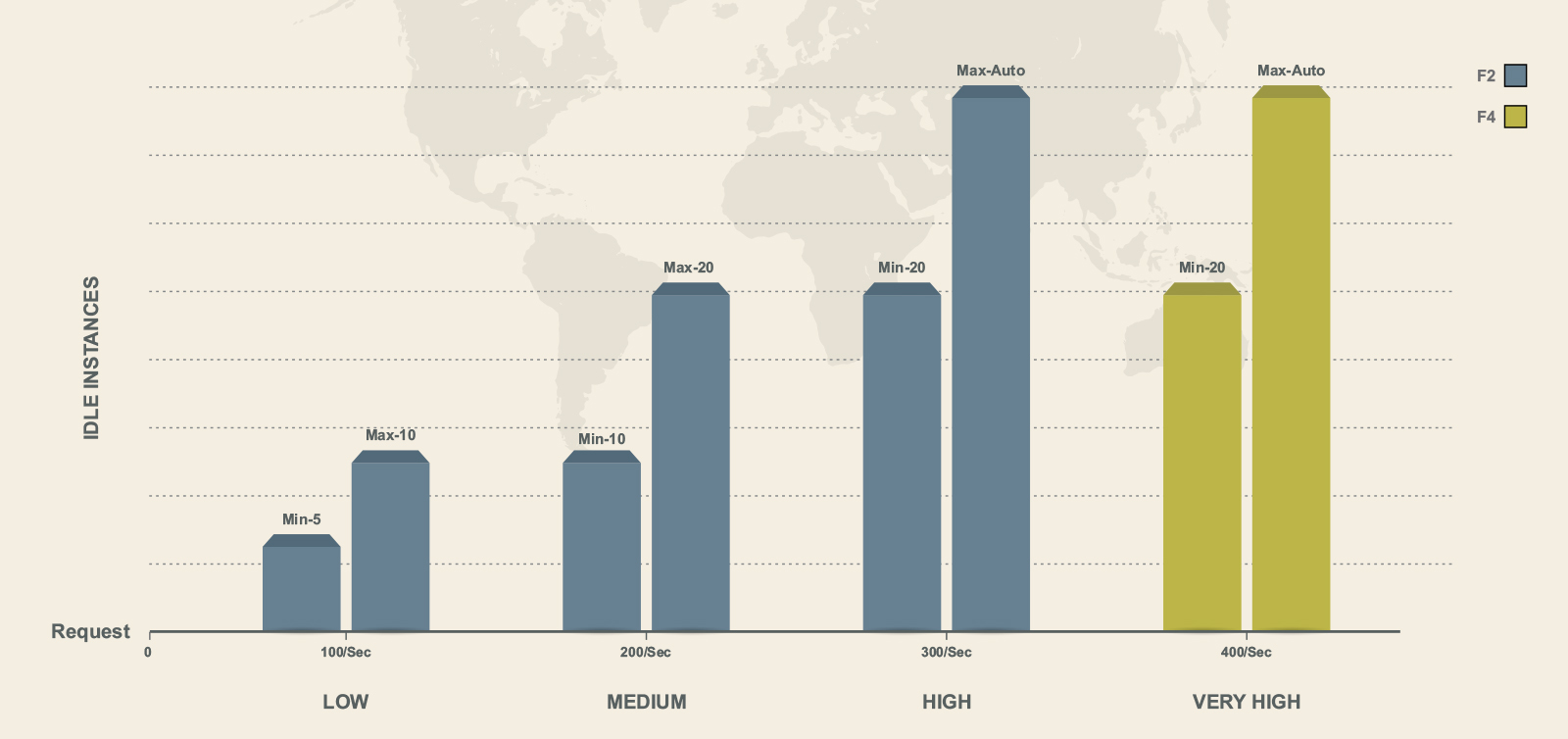
We decided to have different configurations for peak hours and off peak hours:-
Very High –
instance_class: F4
automatic_scaling:
min_idle_instances: 20
max_idle_instances: automatic
High
instance_class: F2
automatic_scaling:
min_idle_instances: 20
max_idle_instances: automatic
Medium
instance_class: F2
automatic_scaling:
min_idle_instances: 10
max_idle_instances: 20
Low
instance_class: F2
automatic_scaling:
min_idle_instances: 5
max_idle_instances: 10
Rather than having just one configuration running throughout the day, we tweaked the settings between low, medium, high and very high, cutting hosting expenses by 1/5th.
About Google App Engine:
If you weren’t aware, Google App Engine is a Google product designed for scalable SaaS product and app hosting. It puts infrastructure in place when scaling is needed, but allows developers to focus solely on code.
In addition, it supports various technologies including Python, Java and PHP, and has a wide range of developer tools available such as Task Queues, CRON jobs, Map Reduce and Channels. To help with offset load problems and other common developer concerns, it leverages auto-scaling, version management, memcache and service-oriented architecture. The end result is faster, easier deployment and management of micro-services.
But it all doesn’t come for free — at least not forever. There’s a set quota for free usage, after which the user is billed.
Key Insight:
What drives up the cost isn’t the back end code, but rather the front-end instance. The more of these concurrent instances that are called upon and the longer they run, the more the cost goes up.
Fortunately, there are a wide range of parameters that control the instance spawning and up-time accordingly so that you aren’t faced with a massive bill from App Engine:
Auto Scaling: Assumed by appengine by default, with Instance Class of F1 if nothing is specified in the app.yaml file.
Instance Class: Used to control the class of Instance to be used in order to serve the application on App Engine. F1, F2 and F4 have their individual attributes (Memory and Processing power).
Maximum Idle Instances: Maximum number of idle instances that are to be maintained by App Engine for a particular deployed version. This parameter plays an essential role in controlling the speed and performance metrics of the application.
A high maximum reduces the number of idle instances gradually when load levels return to normal after a spike. This helps your application to maintain a steady performance through fluctuations in request load. Also, the number of idle instances increases, thus increasing the cost.
A low maximum keeps running costs lower, but can degrade performance in the face of volatile load levels.
Minimum Idle Instances: This defines the number of resident instances that App Engine should maintain for an application’s version.
A lower value for these would degrade the performance but would keep the running costs low.
A higher value would make the server easily handle spikes as app engine keeps these ‘Resident’ instances running at all times.
Minimum Pending Latency: The minimum amount of time that App Engine should allow for a request to wait in the pending queue before starting a new instance to handle it.
A low minimum means that requests must spend less time in the pending queue when all existing instances are active. This would enhance the performance but the running costs would be very high as the app engine charges the user based on the running hours of instances.
A high minimum means that requests will remain pending for longer if all existing instances are active. In this case, the request would have to wait for a longer time before an instance is spawned by App Engine.
Maximum Concurrent Requests: This option defines the number of concurrent requests an automatic scaling instance can accept before the scheduler spawns a new instance.
You might experience increased API latency if this setting is too high. Note that the scheduler might spawn a new instance before the actual maximum number of requests is reached.
As you can see, there is no single best answer in order to accurately manage these settings. It differs from app to app as well as the number of active accounts involved and demand from the user base. As app developers, however, it’s our job to juggle these settings for a more efficient, cost-effective result.
Share what settings work for you and who knows we can together come up with best matrix for cost efficient hosting on Google App Engine!



